Overview of joining data
Sigma supports creating joins in workbooks, data models, and datasets. Joins allows you to combine information from multiple records based on matching information, like a shared column. This expands records horizontally by adding additional fields to each record. Common use cases for joins include unifying data across related tables for analysis and reporting, reconstructing data during normalization, and more.
This document covers:
- An overview of joins.
- When you might want to use a join, versus using another method of combining data, like a union, lookup, or relationship in a data model.
- The differences between the types of joins Sigma supports.
- Join cardinality and some implications.
For steps on how to create joins in Sigma, see Create and edit joins in data models and workbooks, or Join data in datasets.
About joins
Joins allow you to expand records (rows) in a table by adding related fields (columns) from another table. Records are matched between tables based on matching information, like a shared column, and are combined. Each record will have more fields than before, which expands the table horizontally.
For example, you might have two tables with information about stores. The first table contains store sales data (with columns like Store ID, Transaction date, and Transaction amount) and the second contains store location data (with columns like Store ID, Region, State, and City). You might want to join these tables together for a richer dataset, and you can do so based on the matching information between them - the shared Store ID column.
Four types of joins are supported in Sigma: inner joins, left outer joins, right outer joins, and full outer joins. Each join type has a different way of handling matching and non-matching rows, nulls, and direction. For more information on the different supported joins, see Types of joins.
You cannot join tables across connections in Sigma. For more limitations and considerations when creating joins in Sigma, see Considerations and limitations.
Choosing a method of combining data
Joins are not the only way to combine data based on related information in Sigma. Depending on your needs, you might instead want to use a union, a relationship in a data model, or a lookup. Each way of combining data suits different use cases and sets of data. In summary:
Skip to:
Joins versus unions
While both joins and unions result in the creation of a new table, they expand data in different ways. Joins expand individual records (rows) by adding new fields (columns) to each record, creating a wider set of data. Unions expand data by appending tables with similar structures together, creating a longer set of data.
If you have two sets of data that are similarly structured (same record definitions, columns, and data types) that you want to “stack” on top of each other, unions might be suitable. For example, if you have a table with employee sales records for Q3, and want to combine these records with another quarter’s worth of the same information, you likely want to use a union.
It is important that the columns in the two tables have the same data types and record definitions. For example, if you have two tables, each with an ID column, but one table has the ID column as a number and the other as a string, you will not be able to union these tables together. Alternatively, if one of the ID columns contains 4 digit IDs and the other 8 digit IDs, you will also not be able to union these tables together.
For the steps on how to create unions in Sigma, see Create and edit unions.
If you instead have related but different sets of data, each with different columns and data types but with some matching information, joins might be more suitable. For example, you might have one table with employee biographical data (such as Employee ID, Name, Tenure, Location) and another table with employee sales records (such as Employee ID, Monthly deals closed, Total sales volume). If you want to combine them together for a richer set of employee data, you can join these tables together using the common Employee ID field.
For more information on the types of joins, see Types of joins.
Joins versus data model relationships
Relationships in data models are a way for you to define join logic between two tables. When using a relationship, the specified join is only performed when a user adds the columns to a workbook element. This contrasts with joins, where every time you access the modeled data, the join is performed in the underlying SQL. Depending on the size of your model and data set, this can be costly or have performance impacts.
If you have data that you know most of your user base wants to readily access, you might want to use a join. However, if you know only a subset of your users need specific columns from a related table, you might prefer to use relationships. Relationships allow these users to add columns from another source table when needed, instead of performing expensive joins that not all users might need.
Relationships in data models only support many-to-one or one-to-one joins and use a left join type. For more information on relationships in data models, see Define relationships in data models and Use related columns in a workbook or data model.
Joins versus lookups
Lookups allow you to add data from one element into another. You can add one or more columns from an external table while preserving the structure and number of rows in the table you are adding to - similar to a left outer join (see Types of joins). Unlike joins, lookups do not result in the creation of a new table.
When you have a small number of specific columns you want to enrich your dataset with (such as adding one or two additional fields to a table), using a Lookup might be simpler and faster than creating a join.
However, if you want to combine larger amounts of data together (such as one or more tables), or want behavior similar to an inner, right outer, or full outer join, you might prefer using a join. See Types of joins.
For steps on how to create lookups, see Add columns through lookup or the function documentation for Lookup.
Types of joins
Sigma supports 4 join types: inner joins, left outer joins, right outer joins and full outer joins. Each join type has different behavior in terms of what rows are preserved in the join, and how matching and non-matching rows are handled.
For example, a business may have a database with information about their sales and inventory - containing tables with information such as store transactions, product types, store inventory, and customer records. These tables can be combined in various ways, using the different join types, to answer different business questions:
Inner join
Inner joins are useful when we want to find records with matches, or valid relationships, between tables. Take the following two tables for example:
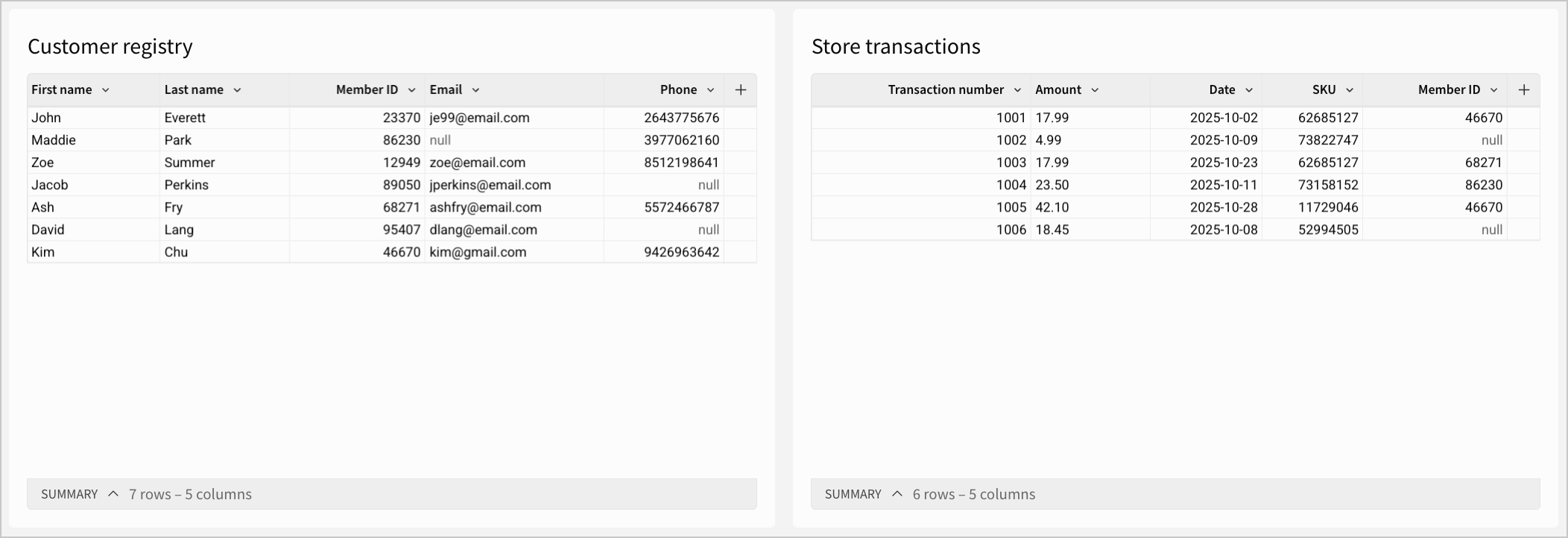
The Customer registry table contains customer data records, with fields like customer First name, Last name, Member ID, Email and Phone number. The Store transactions table contains purchase records, with fields like Transaction number, Amount, SKU (stock keeping units), and Member ID of the purchasing customer.
There are some null fields in both of these tables. For example, the Store transactions table has nulls where purchasing customers might not be registered with a membership.
If you wanted more information about the purchasing behavior of customers with memberships, you could use an inner join:

In the table above, the Member ID column (present in both tables) is used as the join key. Only records with matches are kept, so all member IDs in the Customer registry table without a corresponding ID in the Store transactions table are removed.
The join results in a table with records of only members that have made purchases in the past. Some members can appear in this table more than once, indicating that they have made multiple purchases. This data can be used for calculations such as finding total spend from a specific member over time.
Left and right outer joins
Left and right outer joins are useful when you want to preserve all the records in the one table, and only include matching records from the other table. The left and right outer join types are functionally equivalent, with the only difference being which table’s records are preserved in the join. In a left outer join, all records from the left table are preserved, and in a right outer join, all records from the right table are preserved.
The “left” and “right” tables refer to the position of the tables in a join clause. The left table appears before the JOIN keyword, and the right table appears after. In Sigma, by default, the left table is the first table you select when entering the join interface (appears in the Join with dropdown). The right table is the second table selected, and appears under Selected source.
Left outer joins are more commonly used (tables are often read left to right), but if your database has other tables using right joins, you might want to use a right join for consistency.
For example, you might have an additional In-stock items table with all products that are currently in your inventory, with columns like SKU and Available quantity.
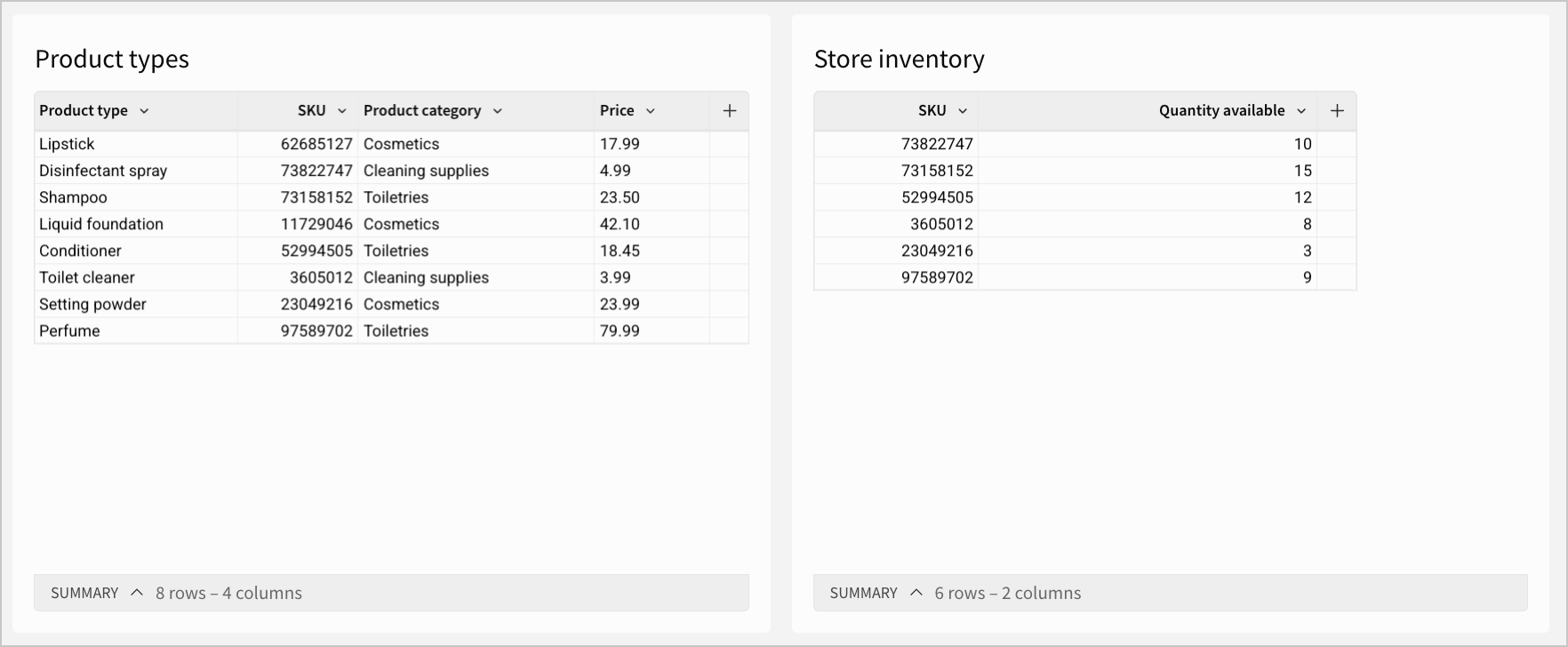
You can perform a left join on the matching SKU column between the tables, with Product types as the left table and In-stock items as the right table. The resulting table looks like:

All of the records in the left Product types table are preserved, and nulls are present where there is no match in the right In-stock items table - indicating that those items are not in stock. The stock detail is useful when deciding what products need to be ordered when resupplying.
If you instead perform a right outer join on the matching SKU column between the tables, with In-stock items as the left table, and Product types as the right table, the resulting table looks like:

The resulting table is exactly the same as the table from the left outer join, with the exception that the table order is reversed, with the left and right tables swapped.
Full outer join
Full outer joins are useful when you want to locate mismatched or “orphaned” records - records that have no match. Returning to the Customer registry and Store transactions tables in the inner join example:
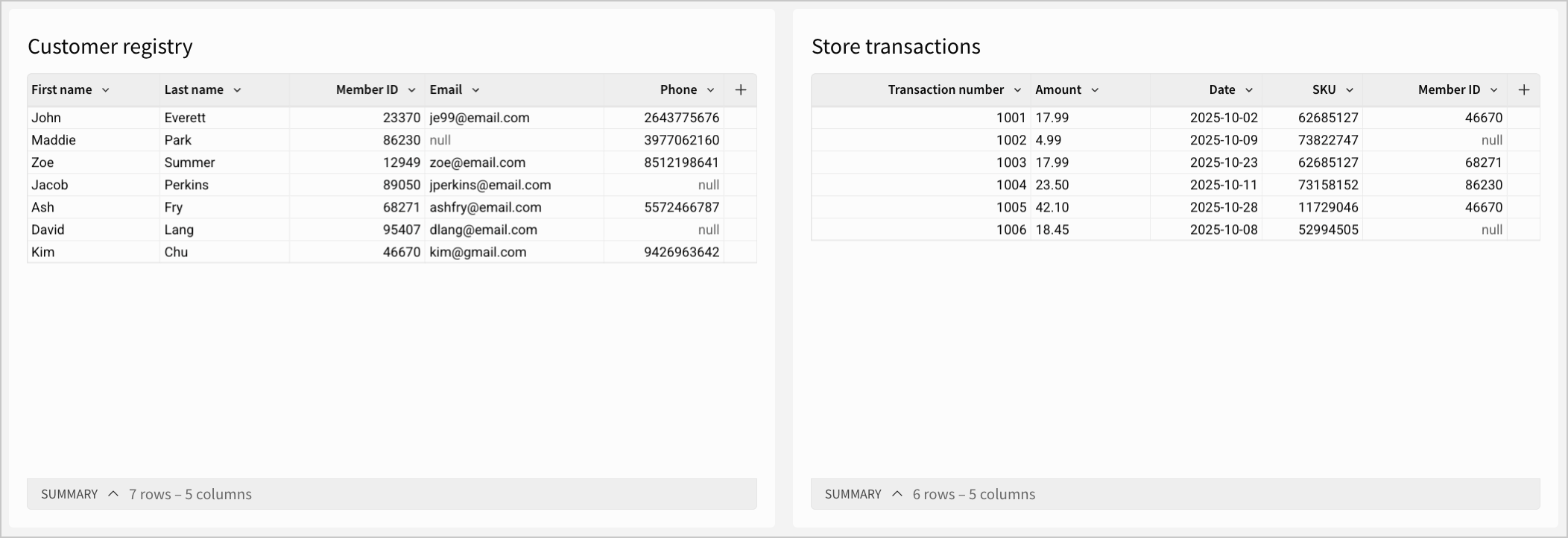
Instead of finding customers who have made purchases in the past, you might instead want to get a holistic overview of the two tables, to see the extent of missing data or mismatches. You can perform a full outer join on the matching Member ID column, resulting in a table like:
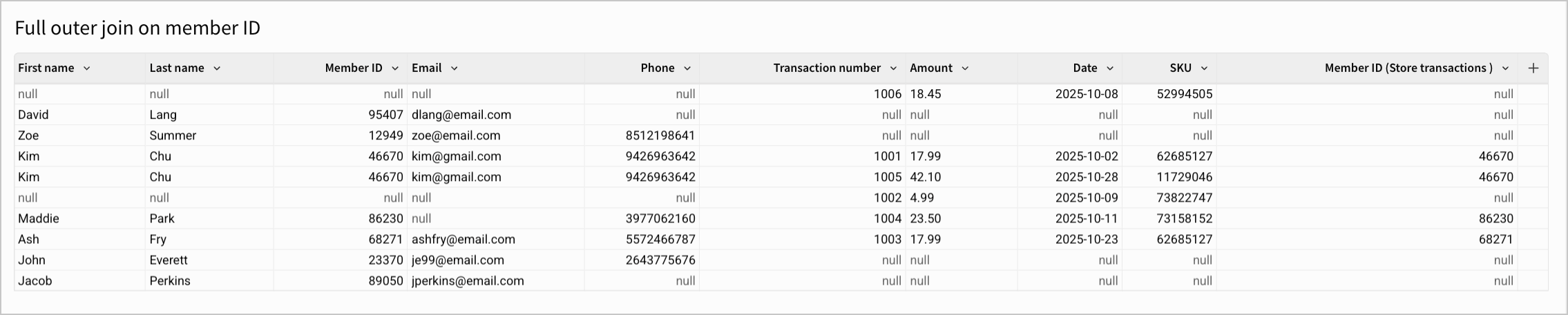
This exposes information like all transactions that occurred without a member ID associated, or how many members are not purchasing items. This can be useful for tasks like finding which members might need additional incentives, like discounts, to purchase items.
Join cardinality
Another factor to consider when joining data is cardinality. In this context, cardinality describes the relationship between tables in a database. Specifically, it describes when two tables are joined, for each entry in a table, how many matching values there are in another table.
There are several types of cardinality, each representing different relationships between tables: many-to-one, one-to-many, or one-to-one.
The cardinality between tables matters for several reasons:
-
Expected output in joins: Knowing the cardinality of your tables can inform what you expect the output of your join to be. For example:
-
For tables with a one-to-one relationship, it is likely that the number of records in your join output does not change, as each row in the left table matches only one row in the right table.
-
For tables with a one-to-many relationship, it is likely that the number of records in your join output increases, as each row in the left table can match multiple rows in the right table.
-
For tables with a many-to-many relationship, it is likely that the number of records in your join output increases (even more so than in a one-to-many relationship). This is because each row in the left table can match multiple rows in the right table, and each row in the right table can also match multiple rows in the left table.
-
-
Performance: Joining many large tables with a many-to-many relationship is more computationally expensive than joining smaller tables with a one-to-one relationship.