Best practices for improved document performance
When Sigma loads a document, Sigma runs queries as necessary to retrieve the latest data from your warehouse. When determining whether to run a query, Sigma first checks different types of caches:
- Retrieve data from the browser cache.
- Retrieve data from Alpha Query.
- Retrieve data from the data platform query results cache (only available for some data platforms).
- Query the data platform for the latest data.
For more details, see Caching and data freshness.
If you want to improve the performance of your document, do the following:
-
Determine what changes to make to your document and implement the relevant changes:
Identify what is slow in your document
If your document is loading slowly, identifying what conditions make it slow can help you identify how you might update it to optimize performance.
Slow document performance can manifest in several different ways. Depending on what you observe, the steps you take to update your document to optimize performance can be different:
A single data element is slow to load
A single data element, such as a chart, pivot table, or table, takes a long time to return and display data.
To improve performance of 1 slow element:
Multiple data elements consistently load slowly
An element in the document, if loaded individually, loads quickly. However, when loading a document with multiple visible elements, the elements load more slowly.
To improve performance:
Multiple data elements intermittently load slowly
All elements load slowly during the day, but load more quickly outside of business hours.
To improve performance:
Control values are slow to populate
The document loads quickly, but the values in list values controls are slow to populate.
Optimize document structure
If one or more elements are consistently slow to load, optimize the structure of your document, such as a workbook, to take full advantage of the optimizations that Sigma includes to accelerate loading data elements:
- Source data elements from 1 main parent element.
- Denormalize data in your data platform or in a data model.
- Perform joins only as needed.
- Filter efficiently.
- Hide or remove unnecessary data.
- Use custom SQL elements sparingly.
Use parent elements as data sources
Because of how Sigma uses various caching techniques to reduce queries made to your data platform, Sigma recommends using a parent-child element structure in a document.
Instead of sourcing each element directly from a table in a data model or your data platform, bring the table into your document and use it as a parent for other elements in the document that use the same data source.
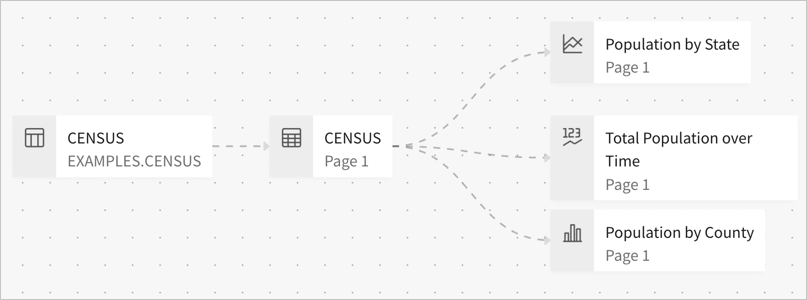

The same guidance applies if your source is custom SQL instead of a data platform table. Use 1 custom SQL element as the source for other elements querying the same data when possible.
When you use a parent element, the child elements can take advantage of the caching provided by Alpha Query. You can ensure Alpha Query is used more frequently by configuring data loading for the parent element as well. See Decide whether to configure data loading.
Denormalize data in your data source
The structure of the data being queried by Sigma is important to ensure fast performance in Sigma.
If your data is redundant, overly complex, or not optimized, you might encounter performance issues in the elements using that data as a data source.
When possible, denormalize your data frequently and early on in the data stream, such as in your data platform to avoid slow query execution. To determine if denormalization makes sense for a particular data source, review how the data is used in Sigma and identify tables that can possibly be consolidated. For details on denormalization in databases, see Denormalization in Databases: When and How to Use It from Datacamp.
You can also perform data modeling in Sigma data models, setting up relationships between tables with relevant complementary data instead of extensive joins, and adding calculated columns to the table in the data model to move calculations upstream in the data analysis process.
By consolidating calculations and logic into 1 table, you can eliminate repetitive calculations and optimize query performance.
Perform joins only as needed
If you need to combine data from different data sources in your analysis, you can use a join or union.
However, whether and where you perform a join in your analysis can affect the performance of the document that uses the joined data.
Instead of joining tables from your data platform, add the tables to a Sigma data model or workbook, then perform a join. If you do not need all the columns in the join for all downstream analyses, consider setting up relationships between the relevant tables instead.
When using relationships, Sigma only performs a join if the related columns are used in the downstream data. Using a relationship instead of a join helps avoid complex long-running queries too. See Define relationships in data models.
When you join elements after bringing them into a document, you can take advantage of the prefetch queries performed by Alpha Query instead of querying the data platform directly with a complex join query.
Another option to accelerate the performance of joined data is to flatten the tables resulting from a join by materializing intermediate results. See Decide whether to use materialization.
If none of those options work, return to your data. Continue performing more denormalization to reduce the depth and granularity to make it easier to query.
For the same reason, if you use lookups in a data element, perform the lookup, then create a child table and use that child table as the parent element for elements in the document that use the same data source.
If you perform complex calculations to achieve data transformation, such as extracting columns from JSON data or handling Array-formatted data with functions like ArrayLength, perform those transformation tasks upstream in a data model or in a grandparent element in a workbook so that the query can run and be cached.
Filter efficiently
Applying filters to your data can be an excellent way to reduce the data that is loaded. However, consider where and when you filter data to improve performance.
If you frequently apply the same filters to individual data elements, move the filters to a parent element instead. If you want the filters to be easily modified by users interacting with the document, move the filters to control elements that target the parent element.
For example, if you have 1 document with Google Analytics events that you want to filter to show results only for 1 host name and the last 30 days, add the filters to the EVENTS table in the document (or in a data model) instead of applying the filter to every table and chart.
Hide or remove unnecessary data
If large sets of data load slowly, consider hiding or removing data to help Sigma run more efficient queries.
For example:
- Hide or delete columns that you do not need in your analysis. Removed columns can always be added again from the Available columns option.
- Place data elements on relevant pages so that you only load the data you need for each page.
- Collapse groupings on tables where you don’t need to see underlying rows of data.
- Hide the summary bar for tables if you do not need it.
Use custom SQL sparingly
When you write SQL to query your data platform directly, the results can be slower to load than creating a table element in Sigma that uses the relevant table in your data platform as a data source.
Custom SQL elements can be slower to load because of how Sigma ensures reliable results. Sigma runs 2 queries:
- A DESCRIBE query to retrieve the expected schema of the returned data
- The SQL statement that you write
The results of the DESCRIBE query is cached for 36 hours when possible, but if your SQL contains a reference to a control element ({{control-id}}), if the value of the control changes to a value that is not cached, the DESCRIBE query must be re-run.
If the results of your custom SQL element take awhile to load, consider retrieving data using a different method. All elements that use the custom SQL output as a data source must wait for the output of the query to return results before displaying data.
Change settings and configurations
If you have optimized the structure of your document and want to continue optimizing performance of your document, review the following settings and configurations:
- If your document contains 1 parent element with lots of child elements, configure data loading to load the data from the parent element into the browser cache to be prefetched with Alpha Query before loading the child elements that use the same data. See Decide whether to configure data loading.
- If your document relies on a data model, or a tagged version of the data model, and the data isn’t updated that frequently, schedule materialization so that Sigma can retrieve data from an optimized table instead of the raw table in your data platform. See Decide whether to use materialization.
- If your data isn’t updated that frequently and is sourced from a data platform connection that supports a query results cache, such as Snowflake, set a longer query ID results cache timeout. See Set a query ID cache duration.
Decide whether to configure data loading
When deciding whether to configure data loading for one or more elements in your document, evaluate the following:
- Review your data lineage to identify parent elements with many child elements. If needed, Optimize your document structure.
- Review the size of the data for parent elements. Alpha Query attempts to prefetch the entire data table and cache it in the browser. If the entire table can be cached in the browser cache, that data is used, otherwise either 10,000 rows of data, or less than or equal to 1,000 rows if any column contains JSON data, are cached. The element must also return at least 1 row of data.
- Consider grouping levels and hidden columns in your table. Any columns in the parent element that are used in child elements must be visible, and any grouping levels in the parent element must be visible and fully expanded to use Alpha Query.
- Identify if lookups and joins are in use. Alpha Query cannot perform joins and lookups. As a result, any elements that use lookups, joins, or contain related or linked columns, are not a good candidate for data loading. Instead, make a child element of a joined table, configure that child element as the parent element for other and configure data loading for that element.
If your document has elements that meet all of these conditions, follow the steps to configure data loading.
Normally, the element used to provide the data for a prefetch query must load before any child elements, therefore be visible on the same page. However, if you configure data loading, the parent element does not need to be visible.
If a slow-to-load element is in a data model, or otherwise is not a good candidate for data loading, consider materializing the element instead.
Decide whether to use materialization
Materialization improves the speed and performance of your documents in Sigma by writing a copy of a dataset or data element back to your warehouse as a table, or in some cases, a Snowflake dynamic table.
If any of the following apply to your data source, consider materializing the data:
- Queries to retrieve the data take a long time to run, due to complexity or size of data.
- The data is used frequently in documents in Sigma.
Your document structure might need to be optimized for materialization to ensure that the queries run efficiently and successfully. Consider the following recommendations and requirements:
- (Required) Avoid targeting controls and filters to elements that you plan to materialize. Instead, materialize 1 data element, then create a child element and target the child element with relevant filters and controls.
- (Required) Avoid materializing elements that reference dynamic values, such as control values or system functions like CurrentUserAttribute(). If the values in your data change, the materialized data is ignored and a new is query run to retrieve the latest data.
- (Required) Review the other materialization limitations to ensure that the data element that you want to materialize can be successfully materialized.
- (Recommended) Perform materialization on data elements in a data model, then source workbook data elements from the materialized data. Materializing in the data model helps reduce duplicate materializations that can occur if you materialize data elements in specific workbooks. If you schedule materialization in a data model, you can also materialize elements in tagged versions.
If you decide to use materialization, follow the instructions in Schedule materialization for a data model or workbook.