Input tables overview
Input tables are dynamic elements that support structured data entry. They allow you to integrate new data points into your analysis and augment existing data from your data platform to facilitate rapid prototyping, advanced modeling, forecasting, what-if analysis, and more—without overwriting source data.
Use input tables as sources for tables, pivot tables, and visualizations, or incorporate the data using lookups and joins. And when you create warehouse views for input tables, you can reuse the manually entered data across your broader data ecosystem.
This document introduces the fundamentals of input tables (functionality, types, and columns), and explains how Sigma handles the data.
Input table functionality
Input tables enable you to do the following:
- Add new rows (empty and CSV input tables only)
- Add new columns (including data entry, computed, row edit history, and system columns)
- Upload and edit CSV data (max 200 MB, UTF-8 only)
- Input values through keyboard entry
- Paste up to 2,000 rows and 25 columns from your clipboard
- Configure data entry permissions
- Configure data validation
- Protect columns to prevent edits
For information about using this functionality, see Create new input tables, Configure data governance options in input tables, and Edit existing input table columns.
Types of input tables
Sigma offers three types of input tables:
Empty input tables
Empty input tables are blank tables that support data entry in standalone tables independent of existing data. You can edit data at the cell level and add editable rows and columns to construct your table as you see fit.
CSV input tables
CSV input tables also support data entry in standalone tables; however, they allow you to pre-populate the table with uploaded CSV data (max 200 MB, UTF-8 only). You can then edit the uploaded data at the cell level and add other editable rows and columns to construct your table as you see fit.
Linked input tables
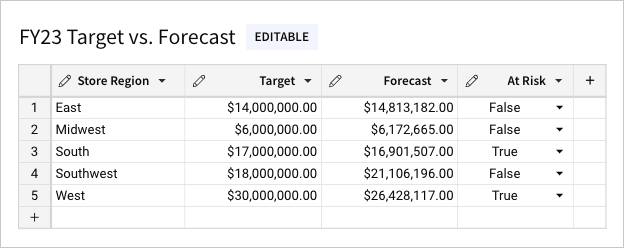
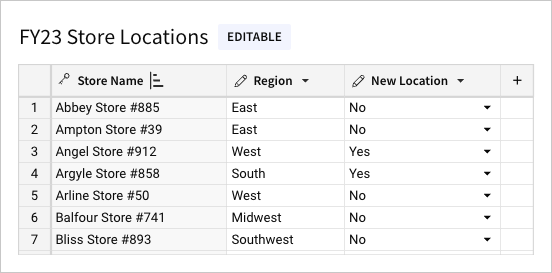
Linked input tables support data entry alongside existing data from other elements in the same document.
As a child element, a linked input table includes one or more linked columns that reference data in the parent element. This includes a primary key column containing row identifiers that establish the table’s granularity. You can then add other columns to augment the linked data sourced from the parent element.
To maintain the data relationship between the input table rows and source data in the parent element, the primary key column must reference static values. All other linked columns can reference variable data, which is continually updated in the input table to reflect live data from the source.
Do not use a calculated column as a primary key column. Using calculated columns, especially generated row numbers (such as from the RowNumber() function) , as primary keys in linked input tables can lead to inconsistent behavior in your document. Since these keys are derived from calculations, they can change with data modifications, such as inserts, deletes or simple edits. This instability may result in:
- Duplicate Keys: Changes in row order can lead to duplicates, violating key constraints.
- Data Integrity Issues: Relationships relying on these keys may break, causing referential integrity problems.
Primary keys should always be stable, unique identifiers, preferably derived from underlying stable data.
Types of input table columns
Input tables support the following types of columns:
Input table data governance
Data governance features (data validation and data entry permissions) allow you to preserve data integrity and enhance the security of input tables. You can also include system-generated columns (row edit history and row ID) to surface input table metadata for auditing and other data management purposes.
For more information, see the following documentation:
- Apply data validation to input table columns
- Customize data entry permission on input tables
- Add system-generated columns to input tables
How input table data is handled
Sigma handles input tables in a distinct manner due to the ad hoc nature of the data. The following information explains how input table data is stored, retrieved, and removed.
Storage
Sigma writes input table data to designated write schemas, as configured by the data platform admin. These destination schemas are identified in the connection details in Sigma (Admin > Connections).
For every input table, Sigma also creates a separate edit log (also known as a write-ahead log or WAL) to ensure data durability, consistency, and recovery. Each edit log contains a sequential record of all input table changes, including information related to user activity and resulting system operations. The edit logs are stored in the same schemas as their corresponding input table data and use the same user configurations (non-OAuth connections), service account credentials (non-OAuth connections), or OAuth credentials (OAuth connections) to write to the data platform.
For information about the write-back architecture for input tables with OAuth, see About OAuth with write access.
Tables containing input table data and edit logs can be easily identified by object names prepended with SIGDS_. To ensure proper input table functionality, avoid modifying any table with the SIGDS_ prefix.
Retrieval
Since Sigma writes input table data to a write-back schema optimized for storage, you cannot query the resulting tables directly. To access input table data in an indirect but query-friendly format, create warehouse views for individual input tables, then retrieve the data from the views using the SQL FROM clause.
Removal
You can delete input table elements in a document (like a workbook or a report), but Sigma does not delete the corresponding input table data written to your data platform. To remove this data, you must delete it directly in the data platform.