
Rank
Assigns a rank to each value in the specified column. By default, the sequence begins with rank 1, and assigns ascending values.
Identical values are considered a tie, and are assigned the same rank. After a tie, the ranking continues with a gap, assigning the next available rank. For example, in a column with the values [1, 1, 1, 2], Rank assigns the values [1, 1, 1, 4]. The value 2 is ranked 4 because there are three values that tie for rank 1, and so it is the fourth ranked value. To assign ranks without gaps, use the RankDense function.
Syntax
Rank([column], [direction])These are the function arguments:
- column
- Optional
- The column referenced to determine rank
- direction
- Optional
- The directional order of column's values:
- “asc”
- Ranks in ascending order, where the smallest values get rank "1"
- Default, when not specified.
- “desc”
- Ranks in descending order, where the largest values get rank "1"
Notes
- Rank assigns ranks based on date, time, numeric, alphabetic, or alphanumeric order, depending on the data type of the referenced column.
- When no arguments are specified, Rank assigns ranks in ascending order based on any sort applied in the table. The Rank column updates when the sort order of the table changes, or when groupings are applied to the table.
Nullvalues are ranked last, after all non-Nullvalues when sorted ascending, and before all non-Nullvalues when sorted descending.
Examples
Rank([Name Count], "desc")In this example, Rank is used to rank female names in Hawaii for the year 2018 by their popularity. The dataset contains a Name Count column that shows the number of instances of each name.
With [Name Count] as the column argument and "desc" as the direction argument, the name with the largest value in the Name Count column has the rank of 1, the next most popular name has a rank of 2, and so on.
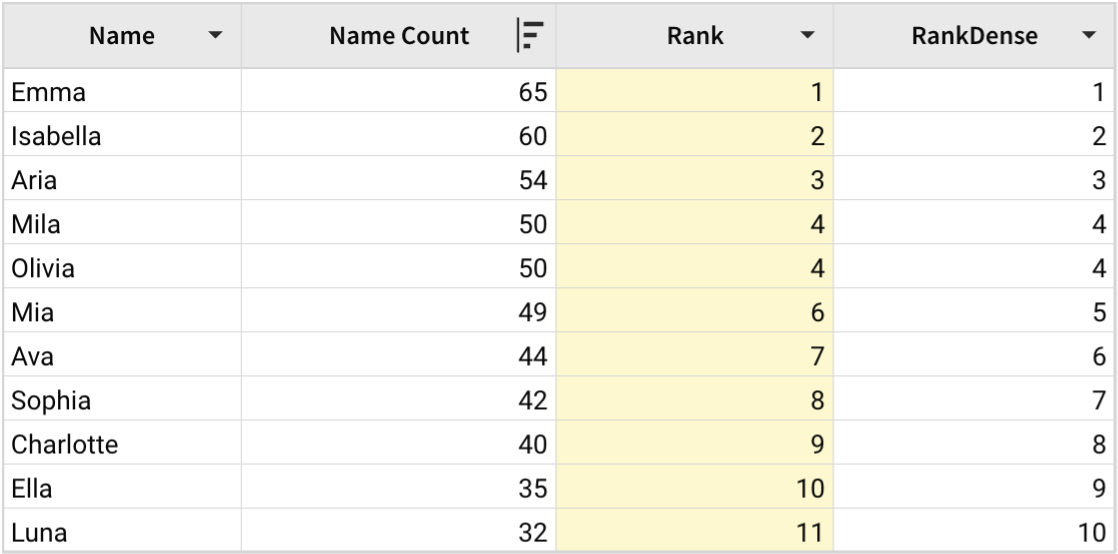
Duplicate values have the same rank. Ranking continues after a gap equal to the number of duplicates. For example, Rank assigns a rank of 4 for the names Mila and Olivia because they have the same Name Count value of 50. There is no rank 5, and the next popular name Mia has the rank 6.
Rank([Number])Assigns ranks based on the [Number] column in ascending order. Null values are ranked last and are tied with one another.